Matt Strassler [Aug. 13, 2012]
I told you a few days ago about the workshop I attended recently at the Perimeter Institute (PI), which brought a number of particle theorists together with members of the CMS experiment, one of the two general purpose experiments operating at the Large Hadron Collider [LHC]. I described the four main areas of discussion, and mentioned a fifth issue that underlies them all: triggering. Today I’m going to explain to you one of two big advances in triggering at CMS that have recently been made public, the one called “Data Parking”. And I’ll also describe my small role in Data Parking over the last ten months, which will explain, in retrospect, some of the other articles that have appeared on this site during that period.
[This article is almost entirely about CMS, but CMS’s competitor, ATLAS, has also made public that they have something essentially identical (I think!) to Data Parking, which they call “Delayed Data Streaming”.]
This is a rather long article. It has to be. It’s not super-technical, but it does involve some of the more subtle issues for doing physics at the LHC, so I have to explain a lot of different things to make the article self-contained. Sorry about that, but I hope you’ll find it’s worth it in the end. If you’re short on time, read the next section, and perhaps the one following.
The Basic Idea Behind Data Parking or Delayed Data Streaming
First, let me remind you briefly what “Triggering” is all about (you can read more about it here.) Each of the two beams of protons at the LHC is made from fourteen hundred little bunches, each one containing a hundred thousand million protons; two bunches cross inside CMS [and inside ATLAS] 20 million times a second. During each bunch-crossing, an average of twenty or so proton-proton collisions occur essentially simultaneously. (The presence of so many collision per crossing is called “pile-up“.) After each crossing, particles stream out from all those collisions and create electronic signals in CMS [or ATLAS] as they pass through all the electronic sensors inside the experiments. With so many bunch-crossings each second, the result is a huge deluge of data, too much to handle; if all of this data were stored it would vastly exceed the computing capabilities available. Until recently, CMS could only store the data from 350 of these 20 million bunch-crossings occurring each second. All the rest had to be dumped in the trash — more specifically, all the data from most crossings is overwritten, and lost forever.
The reason this is acceptable is that the vast majority of proton-proton collisions generate only phenomena that physicists are already familiar with; what’s thrown away doesn’t contain any new or useful information. And conversely, most new phenomena that might be present at the LHC and that we’re really searching for often lead to proton-proton collisions that are easily identifiable as unusual and potentially interesting. For this reason, an automated system — the trigger — can and must quickly scan the data from the collisions and decide which bunch-crossings contain an interesting collision worth keeping. I have to emphasize that this isn’t optional: it is necessary. If the LHC only produced 350 bunch-crossings per second, it would produce a few Higgs particles per year, instead of the few per minute that we’re getting now. And that wouldn’t be enough to discover the particle, much less study it in detail. So the LHC must make more collisions that can be stored, and CMS and ATLAS and the other experiments have to choose judiciously the ones to keep.
But the trigger is only as smart and unbiased as the people who program it, and there’s always the risk of throwing out the gold with the gravel, or at least being less efficient at keeping the gold than one would like. Everyone in the field knows this, and the experimentalists spend a lot of their time and personnel worrying about and tinkering with and testing the triggering strategies that they use.
Data Parking at CMS (and the Delayed Data Stream at ATLAS) takes advantage of the fact that the computing bottleneck for dealing with all this data is not data storage, but data processing. The experiments only have enough computing power to process about 300 – 400 bunch-crossings per second. But at some point the experimenters concluded that they could afford to store more than this, as long as they had time to process it later. That would never happen if the LHC were running continuously, because all the computers needed to process the stored data from the previous year would instead be needed to process the new data from the current year. But the 2013-2014 shutdown of the LHC, for repairs and for upgrading the energy from 8 TeV toward 14 TeV, allows for the following possibility: record and store extra data in 2012, but don’t process it until 2013, when there won’t be additional data coming in. It’s like catching more fish faster than you can possibly clean and cook them — a complete waste of effort — until you realize that summer’s coming to an end, and there’s a huge freezer next door in which you can store the extra fish until winter, when you won’t be fishing and will have time to process them.
So recently CMS, and apparently ATLAS, started storing the data from hundreds more bunch-crossings per second than they did previously; CMS, in particular, is taking 350 crossings per second for immediate processing, and storing 300 extra (and considering adding more) for processing in 2013/2014. These 300 extra are ones they select using novel methods that would previously have been impractical, aimed at signals of new phenomena that are not that distinctive (as least from the trigger’s point of view) and could otherwise have been missed.
Think about it: It’s the equivalent of running the LHC for an extra year, while using a bizarre triggering method for selecting events for storage, one that would never ordinarily have been acceptable! It represents a new opportunity for making (or at least assisting in) discoveries, obtained at minimal financial cost.
Data Parking and (Exotic) Higgs Decays
Needless to say, Data Parking for CMS was an idea that originated within the experiment; only experts would know the details of computer allocation within CMS. But by lucky chance, the possibility of Data Parking was mentioned during a small one-day workshop that I attended in London at Imperial College last September, involving just a handful of theorists and CMS experimentalists. A faculty member at Imperial, who gave the opening talk laying out the goals for the coming months, mentioned that CMS had the capability to store extra data, and asked if any of the theorists thought this capability would be useful for anything in particular. I practically leapt out of my chair!! I’ve been worrying for years about several types of phenomena that I was pretty sure the experiments would start throwing away, once the collision rate became as high as it is now.
Among the worries I had, the one that seemed most urgent involved the Higgs particle. (Recall that back in September we had no reliable experimental hints for the particle yet, but theorists have been thinking about its possible properties for decades.) The point is this: while the experimentalists have (justifiably) paid a great deal of attention to setting up triggering methods that will catch Higgs particles that decay in a fashion that we expect (i.e., in ways predicted for the simplest possible Higgs particle, the “Standard Model Higgs”, and many of its variants), not much attention has been paid to looking for Higgs particles that decay in an unexpected, “exotic” way, such as to new particles that we haven’t even discovered yet that in turn decay to known particles. And the list of possible exotic decay patterns is very, very long! so there’s a lot to think about.
Of course, it is possible the Higgs does not ever decay in an exotic way — so looking for such a process is arguably a long-shot with low odds. But a light-weight Higgs particle, such as one with a mass of 125 GeV, is a very sensitive creature, easily affected by new phenomena — so it’s not a stretch to imagine exotic decays might be present. And correspondingly, the particles emerging from an unexpected exotic decay of a light-weight Higgs often would have too little energy and would be insufficiently distinctive for the collision to be selected by the trigger system for permanent storage. So if we were to assume such decays probably don’t exist and consequently didn’t actively work to assure the trigger would fire when signs of such a decay appeared in a bunch-crossing, well — we might miss a discovery, and even incorrectly draw the conclusion the Higgs particle is of the simplest type, when in fact it isn’t.
Data Parking is the perfect opportunity, and that’s why I jumped out of my chair when I heard about it. If you have a fixed amount of data that you can afford to store each second, any attempt to trigger in a new way means you have to give up one of your old ways of triggering, at least to a degree. It’s a zero-sum game. And you can’t realistically expect people to give up what they consider to be high-odds triggering strategies for what they consider to be low-odds triggering strategies. The community has its biases about the odds, and though I worry a lot about these biases, I can’t say with any certainty that I’m sure those biases are wrong. But if there’s extra storage available, a low-odds but high-payoff opportunity is absolutely one of the things you should consider using it for. So that’s why I’ve been thinking so hard about exotic Higgs decays this year; there are posts on it here, here, here, here, here, here and here. I wrote extensively in those posts about the potential importance of triggering strategies aimed at exotic Higgs decays — but I couldn’t at that time explain that the idea was that this data would be parked, and that I had been working closely with CMS experts at Imperial and elsewhere on the matter. [I’ve also been talking with ATLAS experts as well about the triggering risks, but because ATLAS and CMS’s trigger systems are so different, the two experiments have to solve this problem in completely different ways.]
Triggering is one of the most important and subtle aspects of doing physics research at the LHC experiments, and the reason I was able to contribute to this project, which had to be done very rapidly in order for it to be useful during the 2012 data-taking period, is that I have some experience. I once did some research (co-authored with Kathryn Zurek, now a professor at Michigan) in which it was emphasized (among many other things) that long-lived particles that would decay in flight while traversing ATLAS, CMS and other similar experiments arise much more commonly in theories than is widely appreciated, and that, if present, they might not be noticed by existing trigger methods. This observation inspired a couple of my then-colleagues at the University of Washington, who were members of ATLAS, to join with their ATLAS collaborators at the University of Rome La Sapienza and elsewhere to develop trigger methods specifically aimed at closing this gap in the ATLAS trigger strategy. I worked very closely with them for a long time — indeed I’m a co-author on the relevant ATLAS note — until ATLAS started collecting data and I was no longer allowed to discuss details with them. It is very satisfying to me that this effort has produced a real scientific result — the first one from the LHC that begins to constrain the possibility that the newly-found Higgs-like particle (or anything like it) sometimes decays to as-yet unknown long-lived particles. (ATLAS has a second search completed now. Two related searches, also partly inspired by our 2006 papers, were done at the Tevatron, one by DZero and one by CDF; and at ATLAS and CMS as well as DZero and CDF there are also searches for many other types of more-easily observed long-lived particles [see for example here] that don’t require a specialized trigger strategy.) I was in Seattle back in February to serve on the thesis committee of the University of Washington graduate student who did the bulk of this research, which required not only the development of the new trigger but also entirely new and remarkable methods of using the ATLAS muon detector, ones for which it was not originally designed. His excellent work represents a real success story of interchange among theorists and experimentalists in particle physics.
Now I’ll go into more detail. But before I do, a few definitions:
Useful Definitions

“Transverse momentum”. Momentum is something that has a magnitude and a direction; crudely, it tells you where an object is going and how hard it would be to stop it. Transverse means perpendicular, and at the LHC it refers to perpendicular to the direction of the incoming proton beams. Transverse momentum tells you the part of the momentum that is perpendicular to the beams, as opposed to “longitudinal momentum”, which is along the beam. Transverse momentum is useful because although both transverse momentum and longitudinal momentum should add up to zero after a proton-proton collision at the LHC, there are always particles that travel near or in the beam-pipe after the collision that can’t be measured, so longitudinal momentum conservation can’t be checked. Only transverse momentum conservation can be checked.
“Visible transverse `energy'”. This really isn’t energy, but is instead the sum of the magnitudes of the transverse momenta of the observed energetic particles. It gives a measure of the degree to which particles are flying out sideways, in all directions, after a proton-proton collision.
“Missing transverse `energy'”. This really isn’t energy either. First, you add up (as vectors, including magnitudes and directions) the transverse momenta of all of the observed particles in the event to get the total visible transverse momentum (NOT the visible transverse `energy’!) Since transverse momentum is conserved, if the total visible transverse momentum isn’t zero then there must have been “invisible” transverse momentum to cancel it: momentum carried off by one or more unobserved particles (such as neutrinos or hypothetical dark-matter particles that can travel through the detector without leaving a trace.) The magnitude of the total invisible transverse momentum is called the “missing” transverse energy.

A Few Details About How Triggering is Done
Ok, now back to triggering.
The ATLAS and CMS triggering systems are very similar in some ways, very different in others. Both of them (speaking very crudely) divide the triggering process that looks at the data from each individual bunch crossing into two steps, with similar goals — but the differences in execution are significant:
Level 1 (L1): first, hardware, part of it programmable (and therefore called firmware) is used to make an extremely rapid and crude analysis of the data coming out of a bunch-crossing, looking for any sign of something interesting. L1 is the key bottleneck for the trigger; of the 20 million bunch crossings per second, it can afford only to choose 100,000, i.e. half of one percent. Because of the high speed required, neither experiment can access anything about particle tracks during L1 analysis; only the distribution of energy can be studied, along with a few additional pieces of information, such as whether there might be electron, positrons, muons, anti-muons or photons present. Both ATLAS and CMS are able to study jets (the sprays of particles created by high-energy quarks and gluons), but while ATLAS records only the transverse momentum of each jet, CMS also records some information about the jets’ angles relative to the incoming proton beams.
Beyond Level 1: Then the 100,000 bunch-crossings per second that pass L1 are sent to the next level. There, software begins to take over, but what that software can and can’t do is determined in part by the hardware of the experiment, and by how long it takes to read the data out of the hardware. CMS can in principle look at any aspect of the data at this stage, which they call the High Level Trigger (HLT) though they are still limited by the time it takes to read out and analyze the data from various portions of the experiment. ATLAS has more hardware constraints, and divides this process into Level 2 (L2) and the Event Filter (EF). At L2 only the data from certain parts of the detector, ones that contain information that appeared to be interesting at L1, can be obtained; and only if this subset of the data looks interesting at L2 will the study of the data proceed to the EF, where all the data can be accessed. Again, only a fraction of a percent of the bunch-crossings that pass through L1 will also make it through this second stage to be stored permanently.
More on Higgs Decays: Increasing the Baseline
Ok — now back to possibly-exotic Higgs decays. What’s the relevance of Data Parking?
To explain this I need to first tell you how one can trigger on these exotic Higgs decays using standard methods. Imagine a bunch-crossing in which an exotically-decaying Higgs is produced; stuff flies out from the Higgs decay, and contributes to the electronic signals in the experiment. Will the trigger recognize the resulting data as “interesting”? Clearly that will depend on exactly how the Higgs particle has decayed, so one can’t answer this in general; it has to be case by case.
Unfortunately, there are some types of exotic decays that ordinary trigger methods will almost entirely bypass — trust me, I studied this all winter, and I know it’s true. Does that mean that such decays will be 100% lost? No; there is a baseline of about 1%. And to understand what Data Parking does in this context, one has to understand the baseline first.
What forms the baseline? About 5% of Higgs particles are expected to be produced along with a W or Z particle. About 22% of the time, a W particle will decay to a lightweight charged lepton (more precisely, to an electron, positron, muon or anti-muon), which, if it is energetic enough, will usually be recognized by the trigger system as a good reason to store the data from the corresponding bunch-crossing in which it appears. Similarly, 6% of Z particles decay to an electron-positron pair or a muon-antimuon pair, and these will usually be stored. In these cases, the decision to store the bunch-crossing is completely independent of how the Higgs particle itself decays. No matter how crazy and untriggerable is the Higgs decay, the decay of the W or Z in these collisions will assure the data from about 1% of the exotic Higgs decays will be recorded.
But a 1% baseline is rather disappointing. Can it be increased? The answer is yes, not enormously but by enough to be useful, in the presence of data parking. And here’s how.
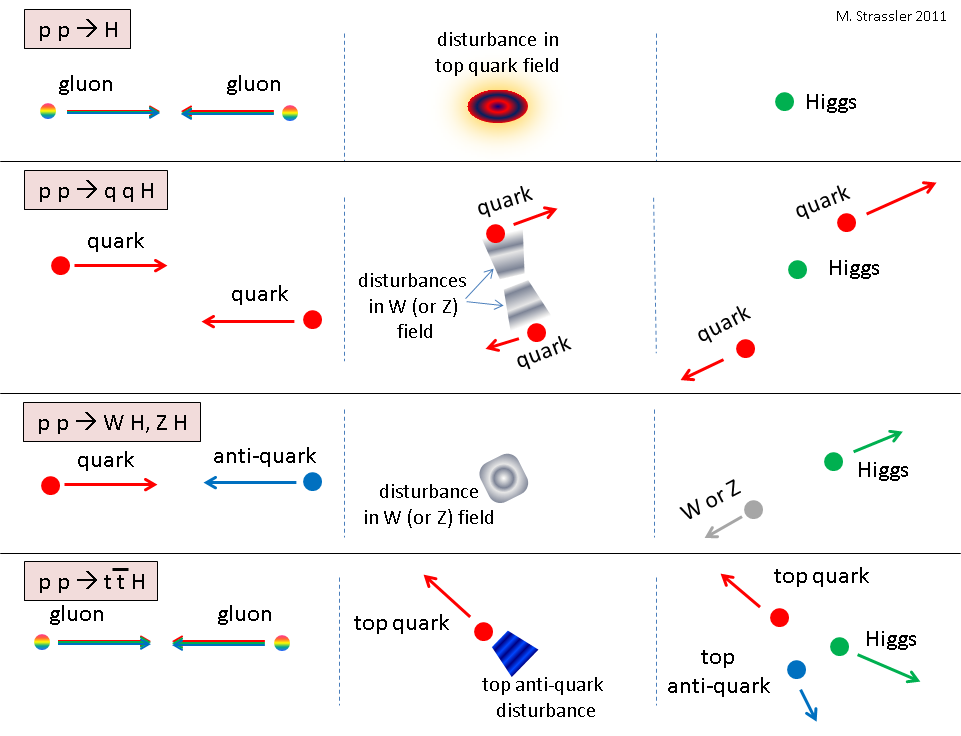
The basic idea is to use another way that Higgs particles are produced, in the process (called vector-boson-fusion, or VBF) in which two quarks (one from each proton) collide, and in the middle of their collision a Higgs particle is produced. (This is described as the p p –> q q H process here.) The two quarks survive and scatter out of the beam, forming jets that enter into CMS or ATLAS at high energy but at a small angle relative to the beam, and thus at small transverse momentum. The presence of these two jets, like the presence of the charged lepton in the baseline events, is completely independent of how the Higgs particle decays. So all that has to be done is have the trigger system identify the two jets (which are called “tagging jets”, since they tag the collision as possibly due to Higgs particle production), and if they have the right characteristics, store the data from that bunch-crossing.

There’s only one problem with this idea: It doesn’t work. You can’t apply this idea at Level 1, either at ATLAS or CMS. There are multiple problems. First, it’s so common that a proton-proton collision produces two jets of this type — or that two simultaneous collisions produce jets such that the bunch-crossing as a whole has two jets of this type — that if you tried to select events in this way you’d choke the Level 1 system. Second, neither ATLAS nor CMS (for different reasons) can select the jets that you’d ideally want, because of the compromises built into the design of their Level 1 trigger systems to make them sufficiently fast. There’s nothing you can do about those design issues; only new technology and a rebuild of the hardware can change this.
Fortunately, there’s a simple work-around. How CMS uses it is too long and technical a story for this article, but what I found in my studies is that no matter (almost) how the Higgs particle decays, if you combine the transverse energy of the two tagging jets with the transverse energy of the particles that come out from the Higgs decay, you often get a reasonable amount of visible and/or missing transverse energy, enough to be interesting for the trigger. This is shown in the figure, where the probability distribution for the sum of the visible transverse energy and the missing transverse energy is plotted, for twenty different types of exotic Higgs decays produced through vector-boson fusion. You can see that the distribution is almost identical in every case.

The CMS people who were leading this project had to do a tremendous amount of work very quickly, and then convince their CMS colleagues; I don’t know enough of the details of that process to describe it properly, so I leave it to them to describe if they choose. In the end, as revealed at the ICHEP conference in July [see page 13 of Stephanie Beauceron’s talk (pdf slides)], CMS’s new Data Parking strategy does in fact include a “VBF” trigger, based in part on the above observation, that identifies a certain fraction of Higgs particles produced with two jets (many of which, though not all, are produced in vector boson fusion) independent of how those Higgs particles decay. This gives another way of agnostically triggering on Higgs particles, and I think I can fairly say, without revealing inside information (since you can basically guess that the whole thing wouldn’t be worth doing if the following weren’t true), that doing so at least doubles the number of baseline events.
Is this useful? Just because you have more data doesn’t mean that you can actually find anything new in it. This was the complaint from some members of CMS and ATLAS during the spring, so several of my young theory colleagues and I set to work to answer that complaint. Though we didn’t have enough people working on it and had very little time to produce results — a month or two, where typically one would work for three to six months on something like this — we did find cases where we could be sure that the new baseline events will be useful, and even cases where they are probably more useful than the original baseline events for making a discovery. In other words, we argued, it’s worth putting this trigger in: the data obtained will definitely be useful in at least some cases. [Big thanks to Tomer Volansky, Jessie Shelton, Andrey Katz, Rouven Essig, David Curtin, Prerit Jaiswal, and Raffaele Tito D’Agnolo.]
How well this effort will really pay off is something we’ll only start to know a year from now, when the data is reconstructed and data analysis takes place. It’s a bit of a gamble, but I think it’s a wise one. Needless to say, I’ll be way more than simply thrilled if the new trigger contributes to a discovery of an exotic Higgs decay. But I’ll still be pretty happy, even if the searches for exotic decays find none, and only put a limit on how often they can happen, if the new trigger helps CMS make the resulting limits considerably stronger than would otherwise have been possible. As far as I’m concerned, helping to optimize the capability of an existing experiment to make measurements of profound scientific importance is honorable work for a theorist.

Other Opportunities with the Trigger at ATLAS and CMS
The CMS talk at ICHEP that I mentioned above also reveals several other types of phenomena being funneled into Data Parking:
- Events with four or more jets above 50 GeV of transverse momentum each
- Events with a possible low-momentum tau lepton/anti-lepton pair
- Events with a very low-momentum muon/anti-muon pair
- Events with a lot of visible transverse energy, or a lot of missing transverse energy (as calculated only from the jets, electrons, photons and hadronically decaying tau leptons in the event, specifically ignoring spread-out distributions of energy)
As far as I know, those are the only public details. I’d encourage my fellow theorists to put some time into thinking about how these unexpected and valuable data sets might be put to best use.
One of the things that was discussed actively at the Perimeter Institute workshop was how to make use of a possible increase in the Data Parking capability at CMS. There were a number of interesting suggestions. But there’s very little time to make the best of this opportunity, because already almost half of the data for the year has already been collected. The reason there’s still any time at all is that data-taking on proton-proton collisions for the year has been extended; it was expected to end in October, but now will continue through December, with the collisions of lead nuclei that were scheduled for November moved into early 2013, and the shutdown of the LHC starting in March. That not only gives a big boost to the amount of data expected but also makes it worth trying to find additional Data Parking possibilities over the next month. Natural opportunities include looking for other ways to trigger on unexpected Higgs decays (now focusing on the specific particles produced in the decays, and less on increasing the baseline) and on ways to find rarely-produced low-mass particles, such as the W/Z/t/H partner particles predicted by naturalness considerations and discussed in Tuesday’s post. It’s probably too late to do anything new about triggering on exotic particles (also discussed in Tuesday’s post); the methods required would take too long to develop.

At ATLAS, it’s not yet clear what’s being put in the Delayed Data Stream, but the fact that it involves over a hundred bunch-crossings per second is clear from this plot, which shows the trigger rates for this year in thousands of bunch-crossings per second (“kHz”), with the amount of delayed data slowly increasing from late May. From the labels on the plot, it would seem they are focusing the delayed data on events with jets (“hadrons”) and on events with low-momentum muons (which often come from bottom quark decays), but that’s guesswork on my part. Equally important, it would also appear they’ve increased the amount of non-delayed data that they are storing to 500 bunch-crossings per second. I look forward to seeing additional public information from ATLAS.
So you see from this that doing science at the LHC doesn’t involve the experimenters sitting back in their chairs, twiddling dials, and waiting for the data to come out of the computer. They’re constantly working, day in and day out, to improve their methods, pushing them to the limit, and beyond. It’s a pleasure and a privilege to work with such creative and intelligent people as they seek to make the best of this magnificent machine.
[I am grateful to a number of members of CMS, especially to Oliver Buchmueller, for many useful conversations about these issues.]



27 Responses
Hey, I think your site might be having browser compatibility issues.
When I look at your website in Chrome, it looks fine but
when opening in Internet Explorer, it has some overlapping.
I just wanted to give you a quick heads up! Other then that, amazing blog!
Sometimes bad weather can affect the signal, but the total amount of
uptime still allows for optimal use. That is the hardest
part about the process of staring a business. Towards the
Knowledge-Driven Bench-Marking of Autonomic Communications.
I am trying to get my head around the scale of these interactions. I understand that a proton is pretty small. So when a bunch of protons meets the bunch going the other way, of the two hundred thousand million protons now occupying the same space only 20 collisions happen simultaneously? Of those 20 collisions are they all head on or does it include glancing collisions too? The proton is made up a soup of gluons and quarks and I imagine a lot of empty space. Even if the proton-proton collision is head on, do some of the colliding protons pass through each other with none of the soup constituents actually hitting another one from the oncoming bunch? Are there fluctuations in the proton where the soup constituents clump to make more dense regions? Is this analogous to two galaxies colliding where there is a extremely low probability of matter from the two colliding galaxies actually making contact?
Most of the proton-proton collisions are not head on and glancing blows are common. That’s why we can afford to make 20 collisions at a time; typically at most one or two of them will be head-on and have a (low) chance of producing a new and interesting phenomenon.
The strong nuclear force is so strong that in fact the soup of quarks and gluons (and anti-quarks) inside the proton is very thick. So in fact the collision of two protons (even a glancing blow) always will involve significant interactions among some of those particles.
However, you should think carefully about what you mean by “hitting each other” or “making contact”.
What does “make contact” mean for galaxies? What you mean is that most of the stars pass by each other, interacting gravitationally, but without the clouds of hydrogen gas passing close enough that they interact electromagnetically, as nearby atoms do. “Contact” means, in this case, “electromagnetic interaction among the atoms in the two stars”.
Meanwhile, if two protons whiz within about 10^-15 meters of each other, a collision occurs, and the gluons and so forth inside the proton will interact via the strong nuclear force. What would “make contact” mean here?
Gluons aren’t like stars. They don’t have an atmosphere and a definite size and there’s no additional force that will allow their atmospheres to interact. [Or if there is, it’s probably not relevant at the LHC, because we would probably have already discovered it from the current experiments.] But also they’re quanta — ripples in gluon fields — and so they’re both inherently spread out through their wave-like behavior and also they’re able to do things that stars can’t. Even without coming closer together than their size — into “contact”, where a new contact force makes something new happen — they can still combine in pairs to make, say, a top quark/anti-quark pair, or a Higgs particle. The closer the gluons approach each other, the more likely such processes become; but there’s no sharp boundary. It’s more subtle than that.
For instance, if two stars hit nearly head on, electromagnetic interactions will be extremely important; the stars will merge, leaving a single, bigger star with emission of a lot of gas and heat and light. If two gluons hit nearly head on, they may (a) pass right through each other (b) scatter off each other at a small angle or a large angle (c) disappear and create a quark and an anti-quark of any type, plus zero or one or more gluons (d) disappear and create a Higgs particle; (e) create a Higgs particle without disappearing; (f) make two photons or two W particles through indirect quantum effects; …….
So you have to be careful about pushing analogies too far… you’ll end up not entirely wrong but also missing key elements.
How does the trigger discriminate, timewise, between the various collisions that take place? If there are 20 million bunch crossings per second and ~20 collisions per crossing, and assuming that the bunches must be separated with space between each bunch in the LHC ring, then the time discrimination must in the nanosecond regime if the trigger is to be able to allocate individual detection events to a specific collision. These detectors are big pieces of equipment and signal wiring paths must have delay times of a comparable amount.
Yes, it takes light, and most of the particles produced in a collision, many tens of nanoseconds to cross from the collision point to the outside of the ATLAS detector. Many of the electronic signals take even longer. And every part of this immense detector is timed to a fraction of a nanosecond. If for some reason any part of the timing goes off on the millions of electronic channels, the resulting data is bad and can’t be used.
Do not underestimate these people.
Matt writes “But the trigger is only as smart and unbiased as the people who program it, and there’s always the risk of throwing out the gold with the gravel, or at least being less efficient at keeping the gold than one would like. Everyone in the field knows this, and the experimentalists spend a lot of their time and personnel worrying about and tinkering with and testing the triggering strategies that they use.”
This had been on my mind in terms of the parameters you use in calorimeter realizations. Is this not of concern considering the trigger used defines for the investigators what fits the parameters or not, has to exist as a new signal. How does one determine that then?
Best,
The parameters used to make sure the measuring devices, such as the calorimeter, are working properly do not have much to do with trigger. The story of how one does this is long and complicated, but the trigger plays a minor role. There are always some classes of events (such as events with an electron of sufficiently high momentum) that will always be selected by the trigger, and that’s always enough information to test out and calibrate the equipment.
As one of a dozen examples: An electron’s momentum can be measured by its track’s curvature in the magnetic field of the experiment, and its energy [which should be the same as its momentum, times c, the speed of light] can be measured in the calorimeter. Z particles, which decay to electron-positron pairs, have a known mass, are made abundantly (many per second) and are triggered with ease when they decay this way. Between these various facts one can already calibrate the electromagnetic calorimeter and (partially) the tracker.
I wonder if someone is thinking to use cloud computing to increase the data processing capacity at LHC. If the data we currently do not process has truly valuable information, why not just investing more money and buying a huge amount of extra computational power from the cloud? I am not sure what’s the cost model at LHC, but I doubt that operating the collider is cheaper than renting a few thousands virtual machines. Amazon EC2 cloud is made up of almost half-a-million Linux servers… there’s a lot of capacity to buy around at a low cost.
I doubt that’s the bottleneck as far as cost, but I’m not expert enough to answer. Still looking for someone to answer the good questions you’re all asking. The super-geeks among you can perhaps learn something from http://cdsweb.cern.ch/record/838359/files/lhcc-2005-023.pdf, though it may be a bit out of date in its details.
Thinking logically: it is not probable that computational capacity is bottleneck here. If they would be able to store more data in realtime, they would do that, cause when it’s stored once, any analysis on it can be done anytime and anywhere, even in few years from now and it still may be valuable. The only logical explanation for such limit is that these 350+300 stored events per second is the most what current storage systems are able to store in realtime. And with that problem no clouds can help, only more dollars spent on newer and faster hardware.
See my response to “B” above, in which I point out that the internet isn’t cost-effective for very high-bandwidth data. And in fact, I wasn’t even taking into account the hugely greater bandwidth of *unprocessed* data.
Also, the compute farms at CERN already use many thousands of computers in a very high-speed network. If you click the (awesome!) link Prof. Strassler shared and check out section 2.6, page 13, you’ll see a diagram showing that the processing is already done in a cloud made up of multiple processing centers arranged in a multi-tiered dedicated network. CERN has no need for Amazon. Since they’re using them all the time, they can probably get lower costs by building their own clouds than by paying for time from someone else’s. Why rent when you can buy?
My guess is that considering Seti or LIGO operations as examples, LHC could configure data in that way across many computers?
You have to realize that the LHC computer people are already using state of the art equipment and methods. I am not a computing expert and do not know the reasons why they do and don’t do things, but you cannot imagine that they are uninformed and have not considered these options.
Seti and LIGO are both examples of applications that are very CPU-intensive but involve only relatively small amounts of data. Again, this is exactly what grids are good for, but it does not describe the LHC data, which, again, is a very large amount of data and therefore probably very expensive to push out to the internet. This sounds like it has all the hallmarks of a bandwidth-bound, rather than CPU-bound, task. This is not what public computing grids are good for. Of course, the LHC already does send data to many computers, thousands of them, just not over the internet, which from the sound of it would be much too slow.
Gerard “t Hooft:No ‘Quantum Computer’ will ever be able to out perform a ‘scaled up classical computer.’ http://online.itp.ucsb.edu/online/kitp25/thooft/oh/22.html
” The HLT (High Level Trigger)- http://www.lhc-closer.es/php/index.php?i=1&s=3&p=13&e=0 have access to all data. At the 1 MHz output rate of Level-0 the remaining analogue data is digitized and all data is stored for the time needed to process the Level algorithm. This algorithm is implemented on a online trigger farm composed of up to 2000 PCs.
The HLT algorithm is divided in two sequential phases called HLT1 and HLT2. HLT1 applies a progressive, partial reconstruction seeded by the L0 candidates. Different reconstruction sequences (called alleys) with different algorithms and selection cuts are applied according to the L0 candidate type. The HLT run very complex physics tests to look for specific signatures, for instance matching tracks to hits in the muon chambers, or spotting photons through their high energy but lack of charge. Overall, from every one hundred thousand events per second they select just dizaines of events and the remaining dizaines of thousands are thrown out. We are left with only the collision events that might teach us something new about physics.”
Interesting article. Two questions:
1) Why not store as much data as the parking lot allows? Processing could be postponed not only to 2013 but to some years later, when computing power has increased.
2) Would it make sense to store a (small) fraction of the bunch-crossings without applying any filter, to avoid any bias? Or at least only a very basic filter? I think, only so you make really sure you do not throw away something interesting that possibly only in the future turns out to be of interest.
1) I’m not sure of the precise pros and cons here. The experts will have to explain it. But there are financial costs.
2) They do that. In fact they store all sorts of things to make sure they understand the filtering done by the trigger. But it doesn’t help: it does not allow you to “make really sure you do not throw away something interesting”. The unbiased (or minimally biased) sample will merely contain a vast number of typical proton-proton collisions that go “splat”, with no high-energy mini-collisions involving any pair of quarks, antiquarks or gluons. Remember only one in 5,000,000,000 collisions makes a Higgs particle, and you’re only able to store about that many bunch-crossings per year. Your unbiased sample can never be big enough to allow you to make or discover something new — which is why you need the trigger in the first place.
What will it take to allow more than 350 results/second to be processed? I assume this is tied to computing capacity so this number might increase over time with improvements in computer hardware.
To give us an idea of the computational requirements, how long would it take a desktop PC to process 1 result? What is the data size of 1 unprocessed result? Has there been any thought of a CMS@Home type of project to offload some processing to willing participants?
I’m sure it will improve over time; I expect there will be some increases by the time the LHC restarts after the shut-down that begins next year.
Experts will have to answer your other questions; I’m sure they have thought about distributing computing power to the public and that there’s probably a fundamental obstruction to doing that.
Grid computing is great for projects that are very CPU-intensive but require very little bandwidth. Remember that the internet is about the slowest thing you can imagine, when compared to the high-performance networking you find in a serious compute cluster. In fact, the best high-speed internet access an ordinary person can buy in most areas is probably 10 times slower than even the cheapest network card you can buy for a PC nowadays (unless somebody out there is still selling those old 10 Mb/s cards).
Those LHC events are pretty high-bandwidth, so anything containing the word “internet” is probably out of the question for that reason alone. A single event is 1.5 MB, so 350 of those a second is over 500 MB/s or 4 Gb/s. That’s the equivalent of 100 DS3 connections, which would run more than $100k a month according to one website I just found (and that sounds believable given other numbers I’ve heard). Assuming that’s accurate, it’s the cost equivalent of buying hundreds of desktop computers every month, so a grid is probably no better than just buying their own computers. (Disclaimer: I’ve never built a grid or anything, I’m just trying to take a stab at a possible answer.)
Yes, there’s definitely no place for any distributed computing within the trigger pipeline, since the way must be cleared immediately for the next data, which come in continuously when the machine is running. However, after the data has been parked or stored, I don’t see any fundamental obstacle to using donated computing like that corralled by the Berkeley Open Infrastructure for Network Computing (BOINC) for SETI@home, LHC@home and the LHC@home Test4Theory. I suspect this approach simply isn’t of much use for the experiments given (1) the sheer amount of data, (2) what I expect to be a relatively small amount of processing per byte, and (3) the existing capabilities of the Worldwide LHC Computing Grid:
http://wlcg.web.cern.ch
As an aside, I actually first heard of BOINC when I was at CERN (as a summer student in 2005). The computing folks at CERN are quite familiar with all of these models, and they spent a lot of time and energy figuring out what would work best for their needs.
This article was the first I’d heard about Data Parking or Delayed Data Streaming. I came out of my LHC physics classes a few years back with the (apparently mistaken, or at least outdated) impression that the ~350 events/second limit was set by the available bandwidth to storage, rather than by any pre-storage processing. So it’s quite a pleasant surprise for me to learn that there is some other place to shove additional data, and that the experiments are making good use of it.